
Introduction

It doesn’t matter if you are tech-genius or a random street dancer that heard about machine learning and decided to look it up out of curiosity or raw passion. Getting introduced into these concepts the wrong way can pretty much feel like being dropped out of a helicopter into the middle of the ocean. I was introduced into these concepts the not-so-friendly way and trust me, it wasn’t fun at all, that’s why I am devoting my time to write this article in a simplistic, beginner-friendly and engaging way.
In this article, while keeping things simple, I will dive a little deep into explicitly explaining what exactly supervised and unsupervised machine learning means in such a way that even a beginner or non-tech person can digest the information without getting constipated by its complexities.
With that out of the way, let’s get down to what brought us all here.
Machine Learning is broadly divided into 2 main categories: Supervised and Unsupervised machine learning.
What is Supervised Learning?

Supervised machine learning involves the training of computer systems using data that is explicitly labeled. Labeled data here means that the input has been tagged with the corresponding desired output labels. The machine learning algorithm (model) learns from this labeled data through an iterative process which then enables it to perform future predictions.\
For example, here is an analogy to help you have a grasp of this concept.
Just think of supervised learning algorithm as students who are given vast amounts of practice problems(data) and instructed to find methods for solving them by finding patterns between the information within these problems and their associated answers(output).
In the above scenario, the objective then becomes to be able to find the most effective data (practice problems) to feed to the most effective algorithms (learning styles), in order to obtain the best performance (answers)
Supervised learning problems are further divided into 2 sub-classes - Classification and Regression. The only difference between these 2 sub-classes is the types of output or target the algorithm aims at predicting which is explained below.
1. Classification Problem

In classification, the objective is to identify which category an object (input) belongs to. For example, we can be interested in determining if an image contains a dog or cat, color red or black, email spam or genuine, a patient has HIV or Not. Classifications problems in which the categorical target takes only 2 classes as mentioned in the examples above are known as Binary Classification problems. On the other hand, if the target output takes more than 2 values it is a Multiclass classification problem. For example; classifying types of flowers, classifying types of cars, etc
2. Regression Problem
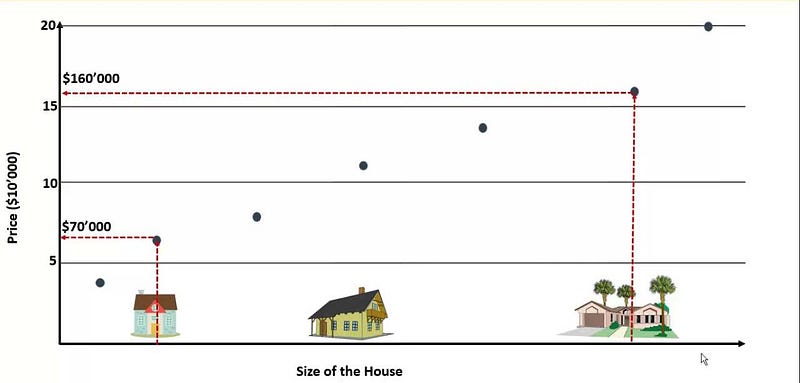
A regression problem is when the output variable to be predicted is a numeric value. This is contrary to classification as seen above. Let’s take for example, you might be interested in determining the prices of houses in Istanbul, weights of men living in Kumbo, salaries of teachers in Cameroon, etc. Price, weights, and salaries are numeric values as illustrated in the image above that show house prices on the vertical axis.
Fun Quiz
This is just to stimulate and cement the difference between Regression and Classification. If you are up for this, then let’s go.
Which of the following is/are classification problem(s)?
- Predicting the gender of a person by his/her handwriting style 2. Predicting house price based on area 3. Predicting whether monsoon will be normal next year 4.Predict the number of copies a music album will be sold next month
At the end of this article, I’m going to provide the answers, so stay frosty.
Supervised Machine Learning Algorithms For Classification and Regression.
The different algorithms outline below to tackle regression and classification tasks are analogous to the different learning styles which each student uses to arrive at an answer in the analogy under classification above. Which of these algorithms performs best in a specific classification and regression problem, is up to you the data scientist to decide.
Staying true to my word of keeping things simple. Here is a list of the most common algorithms used to solve supervised machine learning problems based on specific characteristics of the problem.
- Support Vector Machines
- Linear regression
- Logistic regression
- Naive Bayes
- Linear discriminant analysis
- Decision trees
- Random Forest
- K-nearest neighbor algorithm
- Neural Networks (Multilayer perceptron)
- Similarity learning
For more information on the different algorithms, Check out the scikit-learn website and also the reference links at the end of the article.
Some interesting applications of classification problems are in spam detection, Image Recognition, speech recognition. You can also check out some real-life applications of machine learning that are outlined here
Let’s chill on brains with this mind-blowing fact before we head on..
Did you know Pharaoh Ramesses II is the only Egyptian Pharaoh that was ever issued a passport and boarded a plane to France? Well not literally him but his remains.

What is Unsupervised Machine learning?

Contrary to supervised machine learning, in unsupervised machine learning, the model is fed with data that has no human pre-defined labels. It is up to the algorithm to find hidden structure, patterns or relationships in the data.
Let me share this analogy with you.
Imagine you have no modicum of a clue how to swim and unfortunately your friends take you out for a pool party and intentionally push you in. You are required to figure out how to swim and get yourself out of that freezing pool.
In this analogy, you are the model(algorithm) and the pool is the data. There is no swimming instructor to teach you how to swim, hence the name unsupervised.
Just like supervised learning, unsupervised learning can be split into 2 types: Clustering and Association techniques.
1. Clustering Analysis Technique
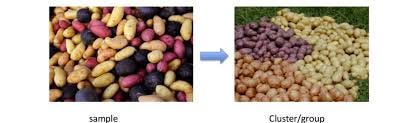
In Clustering Analysis, the algorithm is fed with unlabeled data and it aims at dividing the data into groups called clusters based on some similarity or dissimilarity criteria. Data points that are similar are grouped under the same cluster, just as is illustrated in the image above.
Clustering can be classified into Exclusive Clustering, Overlapping Clustering, Hierarchical Clustering, Probabilistic Clustering which I will not go into this in this article but more information can be found in the links at the end of the article.
Here are some of the most commonly used clustering algorithms in machine learning.
- Hierarchical clustering
- K-means clustering
- K-NN (k nearest neighbors)
- Principal Component Analysis
- Singular Value Decomposition
- Independent Component Analysis
For the curious reader, please refer to the links at the end of the article for more information on these techniques.
2. Association Rule Technique

In association problems, the model learns the relationship between data and then comes up with certain rules. This unsupervised learning technique is about discovering interesting relationships between variables in large databases. For example, people that buy a new home are most likely to buy new furniture, someone who buys a toothbrush is likely to buy toothpaste, etc.
Many algorithms for generating association rules have been proposed. Some well-known algorithms are:
- Apriori algorithm
- Eclat algorithm and
- Frequent Pattern-Growth
Links are included below explaining the individual techniques.
Applications of Unsupervised Learning Techniques.
Unsupervised learning is very useful in exploratory analysis because it can automatically identify structure in data. For example, sub-group of cancer patients grouped by their gene expression measurements, groups of shoppers based on their browsing and purchasing histories, movies group by the rating given by movie viewers.
This article on machine learning provides some interesting day-to-day real-life applications of machine learning.
Answers to the quiz: Predicting the gender of a person, Predicting whether monsoon will be normal next year are classification tasks. The other two are regression.
I know you got it right!!
If you enjoyed reading this article as much I did enjoy writing it, please, feel free to leave a comment, share, like, etc.
References.
https://beltus.github.io/vision/blog/what-is-machine-learning/
https://towardsdatascience.com/explaining-machine-learning-in-laymans-terms-9b92284bdad4
https://www.guru99.com/unsupervised-machine-learning.html#7
https://www.wikiwand.com/en/Unsupervised_learning
https://medium.com/@Mandysidana/machine-learning-types-of-classification-9497bd4f2e14
https://medium.com/datadriveninvestor/classification-algorithms-in-machine-learning-85c0ab65ff4
https://towardsdatascience.com/unsupervised-learning-and-data-clustering-eeecb78b422a
https://www.wikiwand.com/en/Association_rule_learning
https://medium.com/@Mandysidana/machine-learning-types-of-classification-9497bd4f2e14
https://medium.com/datadriveninvestor/classification-algorithms-in-machine-learning-85c0ab65ff4
https://towardsdatascience.com/unsupervised-learning-and-data-clustering-eeecb78b422a
https://www.wikiwand.com/en/Unsupervised_learning
https://www.wikiwand.com/en/Association_rule_learning
Leave a comment